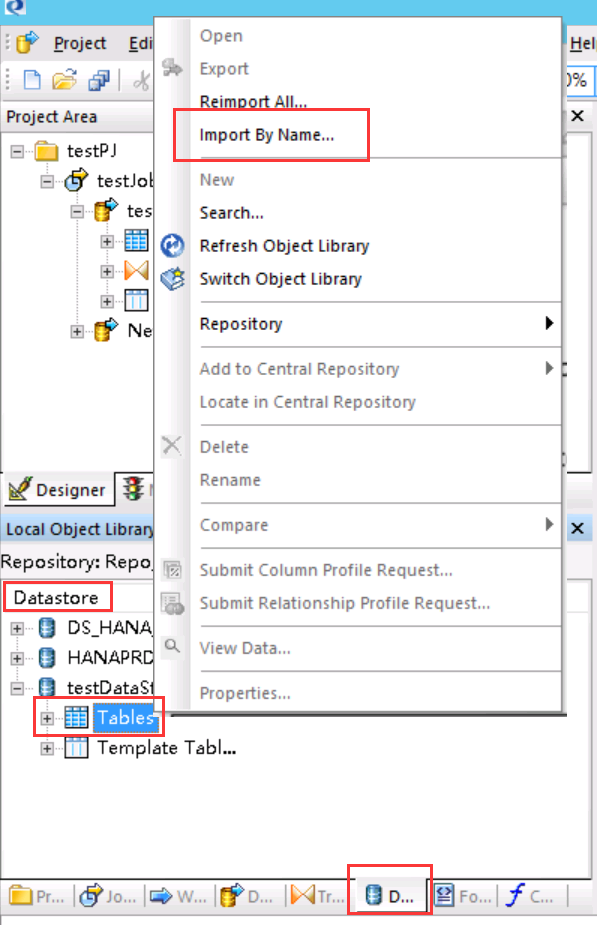
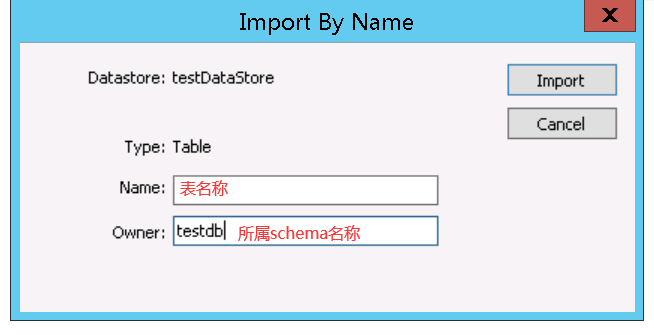
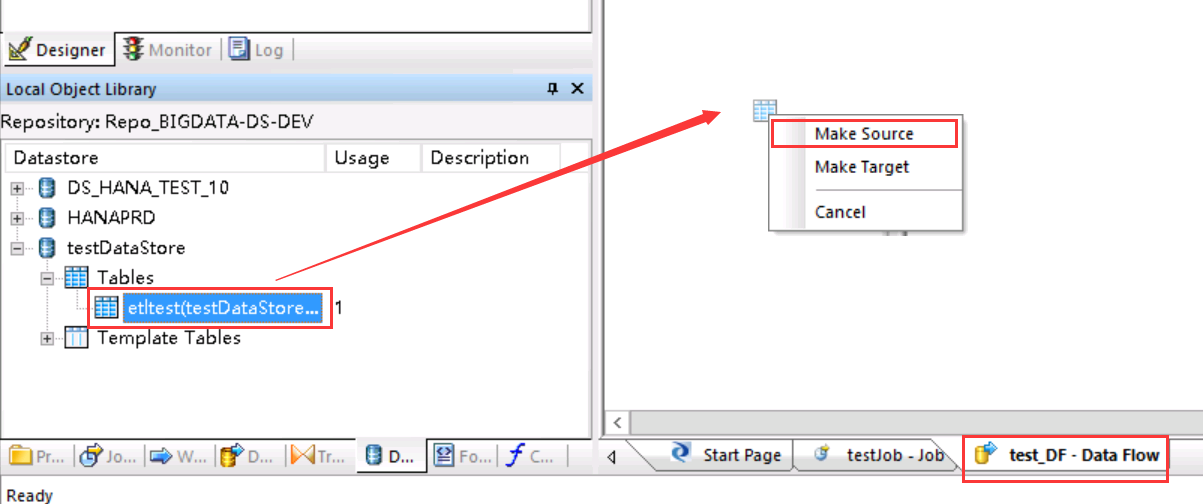
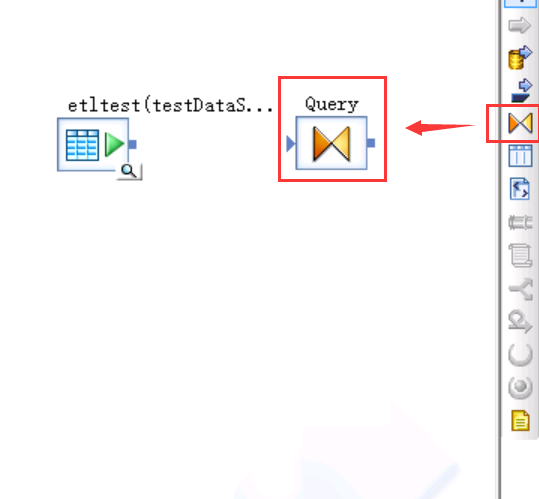
SAP HANA PROCEDURE(sap hana数据库 存储过程)
存储过程
内容引自HANA SQLScript第三部分储存过程-创建储存过程是真长
3.1CREATE PROCEDURE
1 | CREATE PROCEDURE [<schema_name>.]<proc_name> [(<parameter_clause>)] [LANGUAGE <lang>] [SQL SECURITY <mode>] |
The CREATE PROCEDURE statement creates a procedure using the specified programming language
DeepL翻译:CREATE PROCEDURE语句使用指定的编程语言
3.1.1
::= [{, }…] ::= [ ] ::= IN|OUT|INOUT ::= | | ::= DATE | TIME| TIMESTAMP | SECONDDATE | TINYINT | SMALLINT |INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE
| VARCHAR | NVARCHAR | ALPHANUM | VARBINARY | CLOB | NCLOB | BLOB::= TABLE ( ) ::= [{, }…] ::=
输入或输出参数类型可以是标准的基础数据类型与表类型,但INOUT参数只能是标准数据类型
3.1.2 LANGUAGE
默认为: SQLSCRIPT。指定存储过程实现的程序语言
3.1.3 SQL SECURITY
默认: DEFINER,指定存储过程的安全模式
DEFINER:Specifies that the execution of the procedure is performed with the privileges of the definer of the procedure.
DEFINER:只有存储过程的定义者才能执行?
INVOKER:Specifies that the execution of the procedure is performed with the privileges of the invoker of the procedure.
3.1.4 READS SQL DATA
存储过程为只读的,不能包含DDL与DML(INSERT、UPDATE、DELETE)语句(即只能使用查询SQL与DCL语句),如果调用其他存储过程,则被调用过程也是只读的。设置参数会有特定的优化
3.1.5 WITH RESULT VIEW
Specifies the result view to be used as the output of a read-only procedure.将只读取存储过程的输出看做结果视图
When a result view is defined for a procedure, it can be called by an SQL statement in the same way as a tableor view. See Example 2 - Using a result view below.定义了结果视图的存储过程,可以被其他查询SQL用来查询,此时存储过程就像一个表或视图
3.1.6 SEQUENTIAL EXECUTION
This statement will force sequential execution of the procedure logic. No parallelism takes place.不允许存储过程并行执行
3.1.7
[
Defines the main body of the procedure according to the programming language selected.过程的主体由设定的程序语言来定义
3.1.7.1 定义变量
::= [{ }…] ::= DECLARE { | | | } ; <proc_variable>::= <variable_name_list> [**CONSTANT**] {<sql_type>|<array_datatype>}[NOT NULL][<proc_default>]::= [{, <variable_name}…] ::= ARRAY [ = ] ::= ARRAY ( [ { , }…] )
::= (DEFAULT | ‘=’ ) |
::= { | } ::= [{, <variable_name}…] ::= TABLE( ) ::= ( [{, }…])
::= CURSOR [ ( proc_cursor_param_list ) ] FOR ; ::= [{, }…] ::=
::= CONDITION | CONDITION FOR
CREATE procedure proc() LANGUAGE SQLSCRIPT AS
BEGIN
declare a int****default 2;–基本类型变量使用前一定要定义
– 如果某个变量是表类型的变量,可以不用声明,直接就可以使用,这与基本类型变量是不一样的
– ——基本类型变量使用前需要定义
–declare tab_var1 table(a int,b int); 表类型变量可不定义就使用
a := 1;
– a = 1; 基本类型变量赋值时,等号前一定要加冒号,这与表类型变量恰好相反
tab_var1 = select 1 as a,2 as b from dummy;
–tab_var1 := select 1 as a,2 as b from dummy; 这是错误,表类型变量赋值时,只能使用等号,不能在等号前加冒号,这与基本类型变量赋值相反
END;
暂时看到这了:太长了下次再接着看
3.1.7.2 异常处理
3.1.7.3 过程体
3.1.7.3.1 内嵌块
EXECUTION]
内嵌块, BEGIN 、 END是可以内嵌的
3.1.7.3.2 给变量赋值
(
Assign values to variables. An
有关 ARRAY 、ARRAY_AGG、CARDINALITY、TRIM_ARRAY函数请参考后面数组函数
3.1.7.3.3 单个赋值
| CE_RIGHT_OUTER_JOIN (
WITH ORDINALTIY:Appends an ordinal column to the return values.
3.1.7.3.4 多个赋值
Assign values to a list of variables with only one function evaluation. For example,
函数的输入参数个数需与
3.1.7.3.5
You use IF - THEN - ELSE IF to control execution flow with conditionals.
3.1.7.3.6
You use loop to repeatedly execute a set of statements.
3.1.7.3.7
You use while to repeatedly call a set of trigger statements while a condition is true.
3.1.7.3.8
[
[
END FOR ;
You use FOR - IN loops to iterate over a set of data.
3.1.7.3.9
[
[
END FOR ;
You use FOR - EACH loops to iterate over all elements in a set of data.
3.1.7.3.10
Terminates a loop.结束循环
3.1.7.3.11
Skips a current loop iteration and continues with the next value.结束当前循环继续下一次循环
3.1.7.3.12
You use the SIGNAL statement to explicitly raise an exception from within your trigger procedures.
3.1.7.3.13
You use the RESIGNAL statement to raise an exception on the action statement in an exception handler. If an error code is not specified, RESIGNAL will throw the caught exception.重新抛出异常?
You can SIGNAL or RESIGNAL a signal name or an SQL error code.
You use SET MESSAGE_TEXT to deliver an error message to users when specified error is thrown during procedure execution.
3.1.7.3.14
3.1.7.3.15 、、
Cursor operations
3.1.7.3.16
Calling a procedure
3.1.7.3.17
You use EXEC to make dynamic SQL calls.
3.1.7.3.18
Return a value from a procedure.
3.1.8 Examples
Example 1 - Creating an SQL Procedure
You create an SQLScript procedure with the following definition.
CREATECOLUMNTABLE“SYSTEM”.”T” (“ID”INTEGER CS_INT,
“NAME”VARCHAR(30),
“PAYMENT”INTEGER CS_INT) UNLOAD****PRIORITY 5 AUTO MERGE;
insert****into“SYSTEM”.”T”values(1,’a’,10);
insert****into“SYSTEM”.”T”values(2,’b’,20);
insert****into“SYSTEM”.”T”values(3,’c’,30);
CREATE****PROCEDURE orchestrationProc LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE v_id INT;
DECLARE v_name VARCHAR(30);
DECLARE v_pmnt INT;
DECLARE v_msg VARCHAR(200);
DECLARE****CURSOR c_cursor1 (p_payment INT) FOR****SELECT id, name, PAYMENT FROM t
WHERE payment >= p_payment ORDER****BY id ASC;
OPEN c_cursor1(20);
FETCH c_cursor1 INTO v_id, v_name, v_pmnt;
v_msg := v_name || ‘ (id ‘ || v_id || ‘) earns ‘ || v_pmnt || ‘ $.’;
select v_msg from dummy;
CLOSE c_cursor1;
end;
Example 2 - Using a result view
创建带返回视图结果的存储过程:
CREATE****PROCEDURE ProcWithResultView(IN id INT, OUT o1 t)
LANGUAGE SQLSCRIPT
READS SQL DATA WITH RESULT VIEW ProcView AS
BEGIN
o1 = SELECT * FROM t WHERE id = :id;
END;
调用存储视图:
select * from ProcView with parameters (‘placeholder’ = (‘
idid
‘ ,’2’ ));
CREATE****PROCEDURE Proc_test(IN id INT,IN name varchar(3),OUT o1 “SYSTEM”.”T_COLUMN”)
LANGUAGE SQLSCRIPT
READS SQL DATA WITH RESULT VIEW Proc_View AS
BEGIN
outt = CE_COLUMN_TABLE(“SYSTEM”.”T_COLUMN”,[id,name,payment]);
–注:过滤条件一定要使用单引号整体引起来;列名一定要使用双引号引起来;
–如果是字符串,则要使用单引号引起来,因为外层有单引号,所以里面要使用两个单引号代表一个单引号
–o1 = CE_PROJECTION(:outt,[id,name,payment],’”ID” = :id AND “NAME” = ‘’:name’’’);
–上面这句等效于下面两句
o1 = CE_PROJECTION(:outt,[id,name,payment],’”ID” = :id’);
o1 = CE_PROJECTION(:o1,[id,name,payment],’”NAME” = ‘’:name’’’);
END;
select * from Proc_View with parameters (‘placeholder’ = (‘
idid
‘ ,’2’ ),’placeholder’ = (‘namename’ ,’b’ ));
Note
Procedures and result views produced by procedures are not connected from the security perspective and therefore do not inherit privileges from each other. The security aspects of each object must be handled separately. For example, you must grant the SELECT privilege on a result view and EXECUTE privilege on a connected procedure.